NVIDIA AI Released DiffusionRenderer: An AI Model for Editable, Photorealistic 3D Scenes from a Single Video
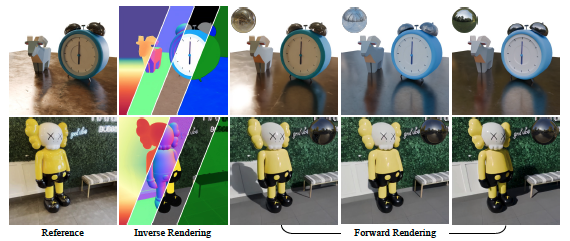
AI-powered video generation is improving at a breathtaking pace. In a short time, we’ve gone from blurry, incoherent clips to generated videos with stunning realism. Yet, for all this progress, a critical capability has been missing: control and Edits While generating a beautiful video is one thing, the ability to professionally and realistically edit it—to change the lighting from day to night, swap an object’s material from wood to metal, or seamlessly insert a new element into the scene—has remained a formidable, largely unsolved problem. This gap has been the key barrier preventing AI from becoming a truly foundational tool for filmmakers, designers, and creators. Until the introduction of DiffusionRenderer !! In a groundbreaking new paper, researchers at NVIDIA, University of Toronto, Vector Institute and the University of Illinois Urbana-Champaign have unveiled a framework that directly tackles this challenge . DiffusionRenderer represents a revolutionary leap forward, mov...